Legal EPG Scraper for ARD TV Stations to Use With tvheadend External XMLTV Grabber
I wrote a Python EPG scraper for the EPG data of the German TV stations broadcast by ARD. It is legal for private use. Here I share the code and my thoughts behind it.
Skip explanations and get the code.
Motivation
Now being rather satisfied with my Media Center in general, one thing was missing: A complete EPG. For DVB-T2 stations it is there, and I’d even say it is the best possible source for those stations. It is fast, most up to date and can be grabbed in short intervals to accomodate for last-minute changes of the TV schedule. However, for the HbbTV and the pure IPTV stations most or all EPG data was missing still. Looking around, it is not difficult to find EPG sources on the net, but none was both free and legal. So I decided to write my own scraper, which I offer here for your own (private!) use.
Legal? How Do I Know?
I asked ARD. I wrote an e-mail asking if it is OK to automatically consume their EPG web pages 2-3 times a day for private use, and they wrote back that this is the case. You may use the EPG data including images as long as you do not publish the data on your own somewhere. That’s nice! Well, I also pay for it with my mandatory German public TV fees, so I already felt somewhat entitled anyhow, but it’s nice to have it “official”.
Update June 2019: The IP of my Raspberry that runs the script got blocked after several weeks of this script running, so I suppose I triggered some automatic mechanism after all. I just wrote to ARD for clarification, let’s see what they respond. A quick calculation shows: 17 TV stations x ~50 shows/day x 14 days = ~12,000 web requests, streched across 4 hours = something just below 1 request/sec…
Update July 2019: Talked to ARD team, and they said: It’s OK – I was blocked, but they are definitly OK with my script. However, they took me into beta-testing a new approach – will write a post about it as soon as I’ve official OK from them! [Edit October 2019: Turns out that this may take quite a while…]
Features
My scraper has the following features:
- Get the EPG data for the coming 14 days
- Convert them into XMLTV format (compliant with this DTD)
- Scrape the following information for each TV show:
- Start and end time (time zone/daylight savings time aware)
- VPS time (if available)
- Duration
- Title and subtitle
- Detailed description
- Credits (if available)
- Keywords
- Categories (derived from keywords)
- URL
- Video and audio properties
- Keeps a list of keywords not categorized to help you to keep the categories up to date
Limitations
- Some things are currently hard-coded that might better be in seperate config files or given as command line argument
- The performance is very slow. I use the Beautiful Soup framework, which is definitely not the fastest on earth. Still, it is great work which saved me a lot of hassle, so thanks to the authors! Grabbing the 14 days of EPG data for the 18 available ARD TV stations takes some 4 hours on my Raspberry Pi 3 B+. But in the end: Why bother? As long as it does not take days… Still, I’d strongly recommend to run it an multi-core computers only (so e.g. not on older single core Raspberries), unless they are just idle. Otherwise, it may seriously impact the general performance of such an SBC.
- Stability: ARD may decide any time to change their EPG layout and HTML code. So my scraper may break down any time. I think I will keep it up to date and adjust to changes within days, but not always having the time for that, don’t depend on it.
Requirements
You need
- python 3 (will run on python 2, but be aware of the time conversion topic below. Also, some minor code changes required.)
- Beautiful Soup (Raspbian: apt-get install python3-bs4 – or use pip)
- lxml (Raspbian: apt-get install python3-lxml – or use pip) – you can also use the built-in XML.etree.ElementTree – main drawbacks: No DOCTYPE in XML, and no “pretty_print”-option, causing the XML to be badly readable for humans. Also, without lxml you need to change the Beautiful Soup parser to html.parser, which makes it slower by a factor of ~2-4. As of now, I did not test if tvheadend accepts a XML without DOCTYPE, but I’d be surprised if not.
If you plan to run this on LibreELEC or CoreELEC, requirements #1 and #3 are not fulfilled. Still, changing the code in a very few places, it still works fine. I found that on Le Potato the html.parser-version is nearly as fast if not a bit faster than the lxml-version on Raspberry Pi 3 B+.
Data Source
This page by Datenjournalist pointed me to the ARD EPG pages, which I use as data source. Using GET parameters, you can navigate to any date or TV station easily. Looking at the HTML response, you find links to a details page for each TV show in the program. The details page contains the information mentioned above in a somtimes more, sometimes less structured form, so using the Beautiful Soup framework and some search and split operations on strings it is possible to get what you need.
Challenges
Most of the work was just diligence – fetch the pages in a browser, look at the HTML code, identify the tags and classes to search for and adjust formats. Since ARD provides the desription of each show already well formatted in a meta tag, even this was a piece of cake.
The Timezone/Daylight Savings Time Problem
The only thing I spent a whole evening to get right was timezone/daylight savings time (DST) conversion. Looking on the time, datetime, pytz and other libraries you’d think it’s just straightforward, but it is certainly not! The problem is that the EPG times given on the ARD pages don’t come along with timezone or DST information. That’s no surprise, since they are German, and all of Germany shares the same timezone, CET, or CEST during DST, respectively. However, I did not want to develop my own code to determine when it’s CET, and when CEST, and I was pretty sure that there are ready made routines. I wanted to put in a time zone agnostic time, and get back a timezone and DST aware time. That this is not as straightforward as you might think becomes clear if you run the following code in python 2 and python 3:
|
1 2 3 4 5 6 7 |
import os import time os.environ['TZ'] = "Europe/Berlin" Time = time.strptime("201905010513", "%Y%m%d%H%M") Timestamp = time.mktime(Time) print (time.strftime("%Y%m%d %H%M %z %Z", time.localtime(Timestamp))) print (time.strftime("%Y%m%d %H%M %z %Z", time.gmtime(Timestamp))) |
Output in python 3:
20190501 0513 +0200 CEST
20190501 0313 +0000 GMT
Output in python 2:
20190501 0513 +0000 CEST
20190501 0313 +0000 CET
Wtf.???
The following code however would work for python 3 and 2 both. Input is a date and time like 201904141654 (YYYYddmmHHMM):
|
1 |
time.strftime('%Y%m%d%H%M00 %z', time.gmtime(time.mktime(time.strptime(ShowStart, '%Y%m%d%H%M')))) |
Output always will be like 201904141454 +0000 – which is correctly converted to GMT/UTC. In my code linked in below however I use
|
1 |
time.strftime('%Y%m%d%H%M00 %z', time.localtime(time.mktime(time.strptime(ShowStart, '%Y%m%d%H%M')))) |
Output will be like 201904141654 +0200 – so the times stay in local timezone, which I think as a minor advantage. Not really important… But be aware that this will be problematic in python 2 and remember to adjust code in this case!
Usage
The Code
Download it here. I tried to put in comments wherever helpful. Also included in the comments the necessary modifications to run it in python 2 and/or without lxml. So if you plan to use it with Kodi on a closed OS, that may help you.
Running it is totally straightforward:
python3 GrabARD.py
Will output ARD.xml in the current working directory. It will also maintain a file with a list of keywords that are not (yet) mapped to a category.
Things to Adjust
At the beginning of the code you’ll find the configuration section – should be self explanatory. For the two text files see text below.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
##################### ### Configuration ### ##################### # Keyword to category assignments file CategoryAssignmentsFileName = "CategoryAssignments.txt" # Where to store uncategorized keywords UnknownKeywordsFileName = "UnknownKeywords.txt" # Name of output file XMLtvFileName = "ARD.xml" # Number of days to scrape from EPG DaysToGrab = 14 # Debug mode? DebugMode = False ### End Configuration ### |
Categories
Looking on the tvheadend web interface, it seems that these categories (aka. content types) are available:
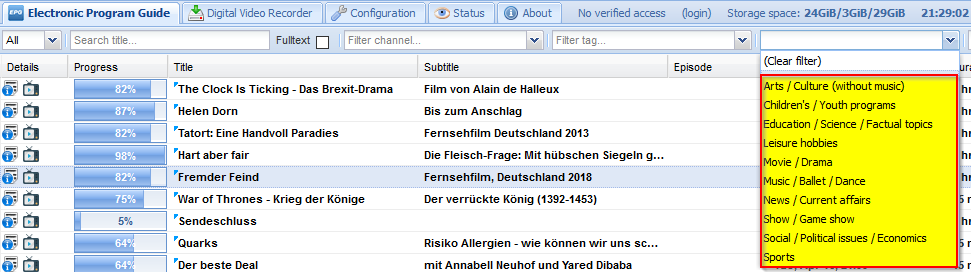
However, some people point out the epg.c in tvheadend can do more, and looking there, indeed subcategories exist. A bit of trial-and-error showed that the XMLtv file needs to have in each <category> tag only the subcategory or the category, not both. This way, both tvheadend and Kodi get along well with it. More precisely, the following categories/subcategories are in epg.c:
- Movie / Drama
- Detective / Thriller
- Adventure / Western / War
- Science fiction / Fantasy / Horror
- Comedy
- Soap / Melodrama / Folkloric
- Romance
- Serious / Classical / Religious / Historical movie / Drama
- Adult movie / Drama
- News / Current affairs
- News / Weather report
- News magazine
- Documentary
- Discussion / Interview / Debate
- Show / Game show
- Game show / Quiz / Contest
- Variety show
- Talk show
- Sports
- Special events (Olympic Games, World Cup, etc.)
- Sports magazines
- Football / Soccer
- Tennis / Squash
- Team sports (excluding football)
- Athletics
- Motor sport
- Water sport
- Winter sports
- Equestrian
- Martial sports
- Children’s / Youth programs
- Pre-school children’s programs
- Entertainment programs for 6 to 14
- Entertainment programs for 10 to 16
- Informational / Educational / School programs
- Cartoons / Puppets
- Music / Ballet / Dance
- Rock / Pop
- Serious music / Classical music
- Folk / Traditional music
- Jazz
- Musical / Opera
- Ballet
- Arts / Culture (without music)
- Performing arts
- Fine arts
- Religion
- Popular culture / Traditional arts
- Literature
- Film / Cinema
- Experimental film / Video
- Broadcasting / Press
- New media
- Arts magazines / Culture magazines
- Fashion
- Social / Political issues / Economics
- Magazines / Reports / Documentary
- Economics / Social advisory
- Remarkable people
- Education / Science / Factual topics
- Nature / Animals / Environment
- Technology / Natural sciences
- Medicine / Physiology / Psychology
- Foreign countries / Expeditions
- Social / Spiritual sciences
- Further education
- Languages
- Leisure hobbies
- Tourism / Travel
- Handicraft
- Motoring
- Fitness and health
- Cooking
- Advertisement / Shopping
- Gardening
The ARD pages do not deliver any content types at all, just keywords. However, the keywords can be mapped to the content types. For this, at the beginning of the code a textfile is read in which contains the category or subcategory to keyword assignmens – general format is:
Category or Subcategory:
Keyword
Another Keyword
Other Category or Subcategory:
Yet another Keyword
# Comment
More Keywords
…
Uncategorized:
Keyword intentionally not assigned to a category
And another keyword to be ignored
…
From these assignments the categories are derived. Blank lines are OK, comment lines starting with # are ignored. Indentations are not mandatory. The “category” Uncategorized contains all keywords you know, but do not want to have a category assigned to. I also included a category “Special characteristics”, which I have seen somewhere in a tutorial, but which does not seem to have any meaning in tvheadend.
You may download my category assignments file.
Also, have a look on the unknown and yet uncategorized keywords output into a file by the script at the end: Some may be worth to add to the mappings. The file will be read in at the beginning of the script if it exists, so over time new keywords should accumulate there.
The categories that come via DVB-T2 are different – the ARD seems to have different ideas about how to categorize their shows. I decided not to follow their scheme – I find my mappings make more sense. However, I still use DVB-T2 EPG wherever available, because having correct schedules is more important than having nice categories – which I ignore most of the time anyhow.
Last thing: Kodi has its own algorithm to pick from the available categories the one that determins the color in the EPG display. So if you want to make sure that a given category “wins”, only give one category (needs code modification!). I did not bother.
Interaction With tvheadend
To get the XMLTV file into tvheadend, you first have to enable the external XMLTV grabber:
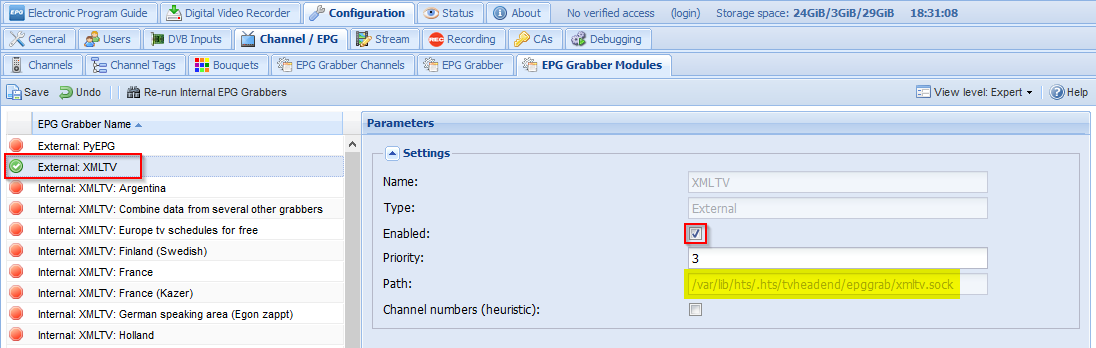
Take note of the “Path” value – we need it in a moment. It points to a socket connection into which the XMTV content needs to be piped, eg by running netcat:
|
1 |
cat ARD.xml | sudo nc -w 5 -U /var/lib/hts/.hts/tvheadend/epggrab/xmltv.sock |
So a way to go would be to create a small shell script:
|
1 2 3 4 |
#!/bin/bash cd /home/pi/EPGgrabber python3 GrabARD.py > LastGrab.log 2>&1 cat ARD.xml | sudo nc -w 5 -U /var/lib/hts/.hts/tvheadend/epggrab/xmltv.sock |
(Don’t forget to chmod u+x it)
Now this can run as a cronjob – done!
Things to Improve
Here’s my ToDo-List to make it better – will do so at no specific schedule:
Remeber uncategorized keywords in a file to accumulate over the daysdone
- Make scraping date and days to scrape command line arguments
- Error handling (none yet…)
Debug mode (No output else)donePut keyword-category mappings in a config filedone
Improve categories to match epg.c from tvheadenddoes not make senseDOES make sense – and done…
- Find ways to make it faster
Alternatives
Of course, when you’re done with your project, you suddenly find another that makes it kind of obsolete… At least xmltv.se seems to be a good source – still I fail to see if they are legal. Also, some channels are missing. And: They provide a bit less/different information as compared to my scraper… Still, worth to have a look! And they have other TV stations as well.
Thanks, for this.
I have an old script that I made a few years ago to display the daily program in the browser.
I used Hoerzu for this, which is much faster.
You can find it here
https://gist.githubusercontent.com/Axel-Erfurt/513e28556a494f475a8341d0188bf659/raw/0becd170e4c88bade52f619427e4fb53c927919f/hoerzuTagesprogramm.py
Thanks for sharing! My concern would be: Is this legal? I myself looked at the terms of use of a few online TV program providers, and all explicitly stated that scraping the content is prohibited. This partly was the reason why I approached ARD directly, in order to be sure to do nothing illegal.
I will ask the company and then let you know.
Hello, this is Jesus.
Thank you for share your work.
If you wish to know the clasification information for an event of the EPG, you can read the ETSI EN300 468, section 6.2.9 (currently v1.17.1) “Content descriptor”. This standard is available free of charge at ETSI and http://www.dvb.org websites.
Merry Christmas
Thanks for this information! And merry Christmas too!
Hi Hauke,
I’ve just given up on my TV’s built-in SAT>IP client, so set up tvheadend and kodi. I’d like to get a reasonable, but definitely provider terms of service compliant, EPG for German free-to-air TV. Grabbing the EPG over the air is slightly incomplete for me and not keeping a tuner busy to do that just seems a bit nicer.
I’m curious, I hope it’s OK to ask – what do you use for your EPG today? Also, is there anything else you could share about ARD’s alternative?
Cheers.
Hi wiggy,
the solution I describe in this post still works, so that would be an option. I in the meantime use a different approach, that ARD did ask me not to share openly. I’ll ask them if I can share the solution with individuals (rather than publishing it). Also, this gives me an opportunity to bring myself into their memory to see if they are done with their new API…
I’ll get back to you via PM as soon as I have an answer from ARD.
Cheers, Hauke
Very useful tool, many thanks for sharing it.
Do you know if it would be ok to share the generated ARD.xml on a server, which would reduce the load on the ARD server?
Do you have a similar script to obtain the EPG for ZDF and the associated channels?
The ARD was specific on this: It’s only for private use – so I suppose they would not really be OK with publishing it. On the other hand: How will they know after all?
On ZDF: No, I did not find a similar opportunity. I looked, but the EPG online structure was rather different. I do not remember the details anymore, but I decided that I did not want to take the effort. Maybe because all ZDF distributed stations were available via DVB-T2 and the EPG was just fine from there.
https://tvprofil.net/xmltv/ seems to have a free ZDF xmltv file. Unfortunately, it does not work for me with tvheadend. I pasted it the same way with nc as it wors very well with ARD.xml:
cat weekly_zdf.de_tvprofil.net.xml | nc -w 5 -U /home/tvh/.hts/tvheadend/epggrab/xmltv.sock
(I have a different installation directory for tvh).
Do you know if there is a subtle format difference required by tvheadend compared to kodi
https://tvprofil.net/xmltv/?channel=zdf
?
Looking at the current XML from your source, i.e. https://tvprofil.net/xmltv/data/zdf.de/weekly_zdf.de_tvprofil.net.xml, two things strike me:
a) The XML has no header – perhaps try to add the line “<?xml version=’1.0′ encoding=’utf-8′?>” as first line to the XML file.
b) The <title> tag has a language flag “hr” (<title lang=”hr”>)- I’m not sure if this may cause the title to be ignored unless you switch your UI to Croatian…
Elsewise, the XML file looks sane to me.
Oh, and somewhere there’s a log file which should state why the file might not have worked… I don’t remember the location, but this should be easy to find.